Questo è una specie di seconda parte del primo.
Product manager: “Buon anno ragazzi. So che sono i primi giorni dell’anno, ma ci sono già nuove feature che si vorrebbe implementare.
Si vorrebbe far mostrare all’utente alcune statistiche, come il numero di volte che è passato allo sportello e anche la distanza, per fargli mostrare quanta CO2 ha fatto risparmiare se le avesse fatto in automobile, quanto pensate che ci si metterà?”
Backend: “Bè, visto che già ci salviamo questi dati sarebbe una semplice query al DB, un’oretta e dovremmo farcela”
Passa qualche ora…
Backend: “API fatta e i dati esposti sono già in produzione”
Frontend: “Perfetto, anche noi siamo pronti, fra poco va in produzione”.
View in produzione, adesso gli utenti possono vederla.
Tutto sembra che stia andando bene, passano alcune settimane e il sito inizia a rallentare, soprattutto la parte delle statistiche.
Il DBA: “Ragazzi, vedo che state usando molte più risorse rispetto l’anno scorso per lo stesso numero d’utenti, qui c’è una query che inizia a macina sempre più dati, è veramente necessaria?”
E così si capisce che il problema è che inizia a risultare pesante la query per il numero di utenti che si hanno, quindi bisogna vedere di trovare un altra soluzione.
E cosa si può fare per diminuire il carico?
Se si volesse fare vedere solo quei dati, quindi per ogni anno far vedere solo il corrente, ci possono essere alcune soluzione.
La prima è denormalizzare il campo, come per il problema che è successo a Justin Bieber per Instagram.
Quindi, ogni volta che inseriamo il dato in database, possiamo anche aumentare un counter.
L’altra sarebbe fare una vista materializzata, da far aggiornare ogni tot, in modo che questa operazione non viene eseguita per ogni utente tutte le volte, ma per tutti e poi diventerebbe un accesso quasi O(1).
Ma se vogliamo fargli invece visualizzare più dati, come per esempio ogni anno da quando è registrato o comunque cambiare queste logiche in corso, ecco che ci viene in aiuto gli OLAP (OnLine Analytics Process).
E adesso un altro DB, ma non è sufficiente il mio OLTP?
Visto che in questo caso parliamo di statistiche, un OLTP riuscirebbe a farle, ma la sua prestazione sono nettamente inferiori a un DB OLAP, che è pensato specificatamente per la lettura massiccia dei dati, più che l’aggiornamento.
Usandone uno d’esempio: Clickhouse.
Quindi si potrebbe creare una pipeline che, ogni minuto, prende gli ultimi dati dal nostro database principale e li inserisce nel nostro OLAP.
Ma se vogliamo dare all’utente un esperienza immediata?
Potremmo l’applicativo aggiungere direttamente questi dati al DB di Clickhouse, ma potremmo avere troppe connessioni parallele e avere rallentamenti alla risposta.
Clickhouse, già di base, ha una serie di connettori per poter gestire i dati che arrivano in tempo reale da varie fonti, per esempio: RabbitMQ o Kafka.
Questo potrebbe migliorare le prestazione delle singole insert in DB da parte dell’applicativo, anche perchè Clickhouse è molto più efficace a gestire bulk insert che singole ( che consiglia anche di inserire batch di 10k o 100k alla volta, come dalla loro documentazione bulk insert).
Un esempio del worflow con una coda Rabbit per gestire le insert.
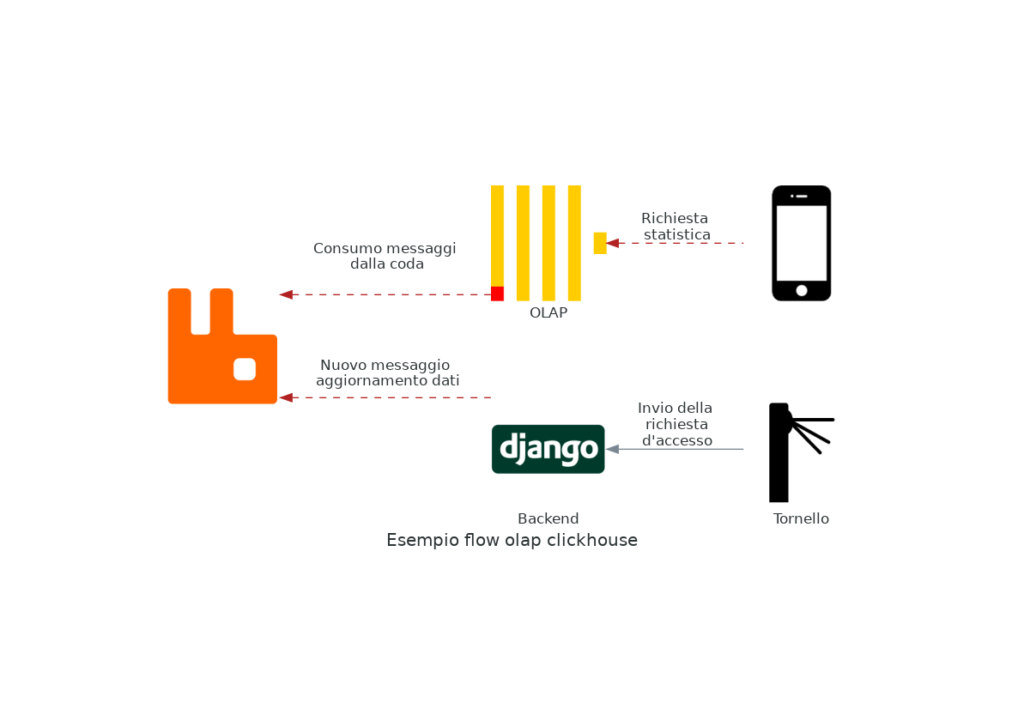
Più spazio al database principale
E qui si può anche spostare il carico di questi dati dal database principale, dedicato a tutte quelle entità che l’utente modificherà sempre, a questo database OLAP.
Ovviamente per queste entità non bisogna aver necessità di modificare, ma se sono eventi o altro che viene registrato una volta e poi letto sempre, è molto utile.
Conclusione
Come ogni cosa, non c’è una soluzione che va bene per tutto e ogni caso è da valutare.
In questo caso, molte delle volte fare query personali su un database OLTP va bene, fino a quando non si hanno troppi dati e nello stesso tempo troppe richieste (se le deve fare l’applicativo per un numero di utenti alto).